


SAM 2 Announced by Meta!
It's Gotten So Better!!!

Segment Anything Model 2 (SAM 2) represents a significant leap in visual segmentation technology, extending the capabilities of its predecessor, SAM 1. This impromtu post talks about the architectural advancements and benefits of SAM 2, emphasizing its superiority over SAM 1.
They just announced this 4 hours back, and I’ve had a chance to skim it briefly. As such, this analysis is based on a high-level understanding and may not cover all the nuances.
Introduction to SAM 2
SAM 2, developed by Meta's FAIR team, is designed to address the complexities of promptable visual segmentation in both images and videos. Unlike SAM 1, which was limited to static images, SAM 2 offers robust performance in dynamic video environments, making it a versatile tool for a range of applications from augmented reality (AR) and virtual reality (VR) to robotics and autonomous vehicles.
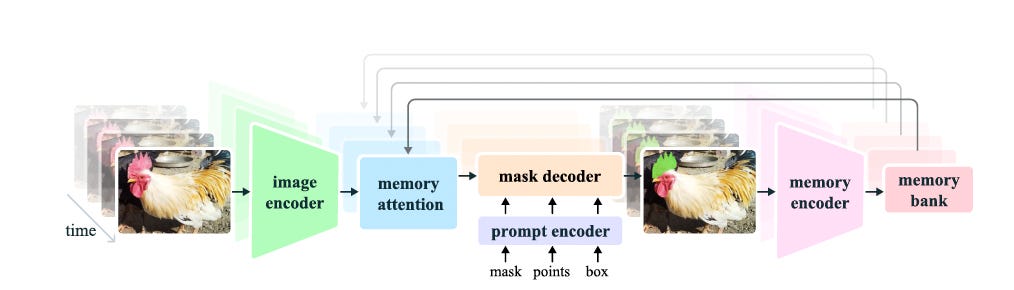
SAM 2 Architecture
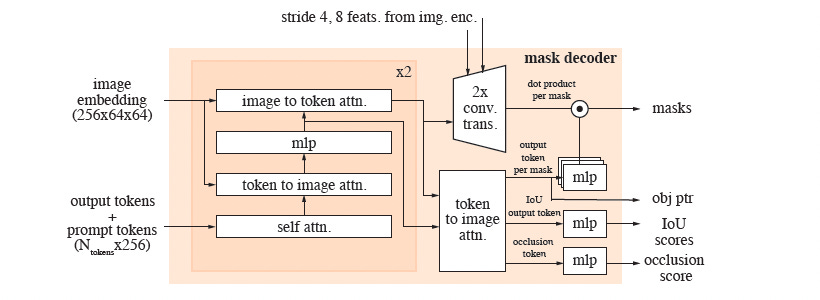
Mask Decoder Architecture
Architectural Advancements in SAM 2
1. Transformer Architecture with Streaming Memory
One of the standout features of SAM 2 is its simple transformer architecture equipped with streaming memory. This design allows SAM 2 to process video frames in real-time, maintaining a memory of past interactions and segmentations. The memory module enables SAM 2 to generate accurate segmentations by referencing previous frames, ensuring consistency and precision across video sequences.
2. Enhanced Promptable Visual Segmentation (PVS)
SAM 2 introduces an advanced PVS task that generalizes image segmentation to the video domain. It takes various input prompts (points, boxes, or masks) on any video frame and predicts a spatio-temporal mask, known as a 'masklet.' This interactive segmentation capability allows users to refine segmentation results by providing additional prompts, enhancing the model's adaptability and accuracy.

Promptable Visual Segmentation task (PVS)
3. Memory Attention Mechanism
The memory attention mechanism in SAM 2 is pivotal for its performance. This mechanism allows the model to attend to past frames and predictions, enabling it to handle the temporal complexities of video data. This approach not only improves the segmentation accuracy but also reduces the need for frequent user interactions, making the process more efficient.
4. Data Engine for Large-Scale Training
SAM 2 is backed by a sophisticated data engine that facilitates the collection of the largest video segmentation dataset to date. This data engine, which involves human annotators interacting with the model, generates high-quality training data for diverse and challenging segmentation tasks. The resulting Segment Anything Video (SA-V) dataset includes 35.5 million masks across 50.9 thousand videos, providing a robust foundation for training and evaluating SAM 2.
Benefits of SAM 2 Over SAM 1
1. Superior Video Segmentation
SAM 2 excels in video segmentation, a domain where SAM 1 was not applicable. Its ability to handle the temporal dimension of videos, manage occlusions, and adapt to changing appearances of objects sets it apart from SAM 1. This capability is crucial for applications requiring precise and consistent segmentation across video frames.
2. Improved Accuracy and Efficiency
In image segmentation tasks, SAM 2 demonstrates a significant improvement in accuracy and speed compared to SAM 1. It is reported to be six times faster while delivering better performance. This efficiency makes SAM 2 suitable for real-time applications, enhancing user experience and productivity.
3. Reduced User Interactions
SAM 2's advanced memory attention mechanism and interactive segmentation capabilities reduce the need for multiple user interactions. In video segmentation tasks, SAM 2 achieves better accuracy with three times fewer interactions than previous models. This reduction in required user input streamlines the segmentation process, saving time and effort.
4. Comprehensive Dataset and Fairness
The SA-V dataset, which supports SAM 2, is geographically diverse and designed to minimize performance discrepancies across different demographic groups. This focus on fairness ensures that SAM 2 provides reliable segmentation results across various use cases and environments, addressing potential biases present in earlier models.
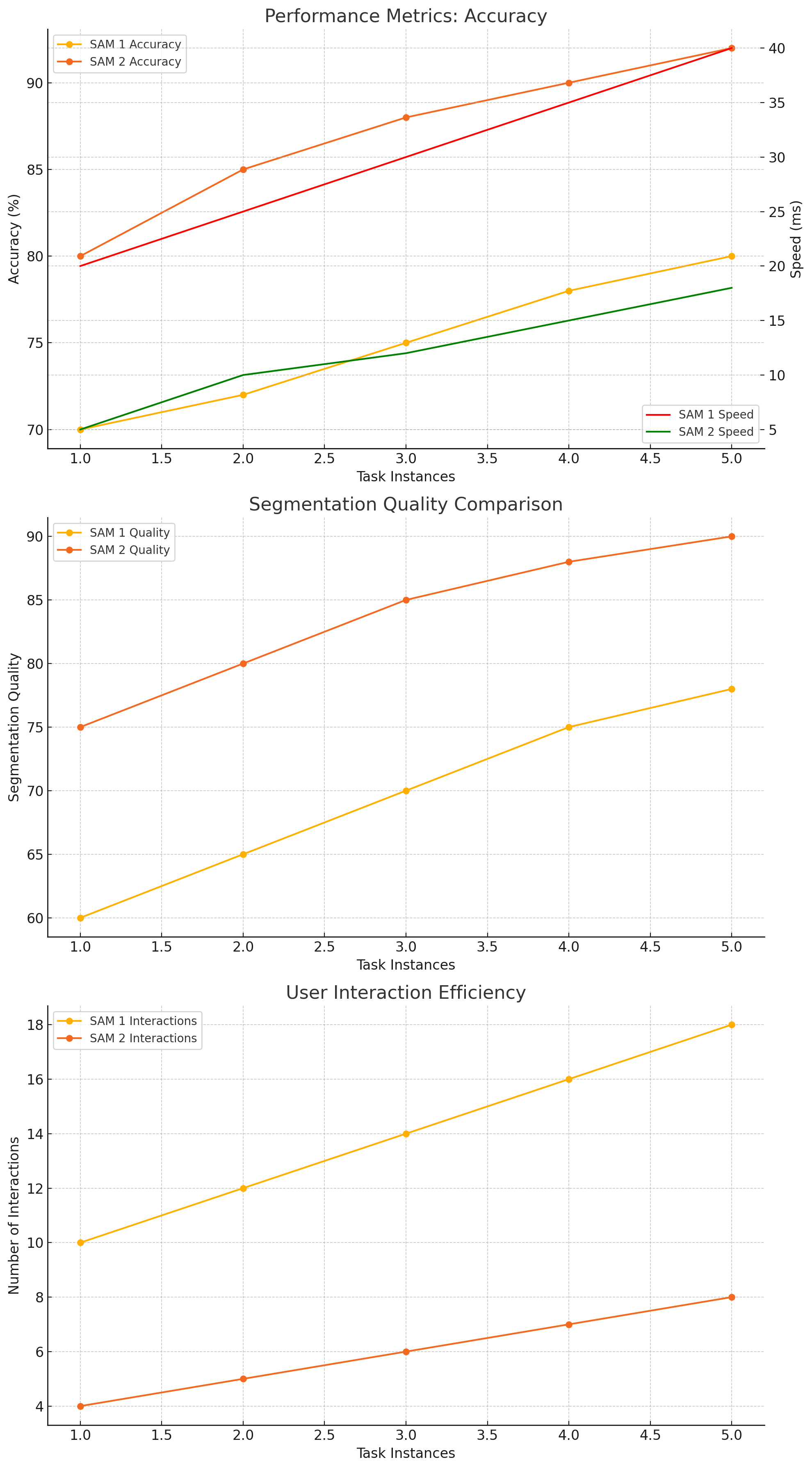
Graph created by Hemanth Dhanasekaran. Data based on SAM 2 research paper.
Please Note:
Performance Metrics
SAM 1: J&F (Jaccard-F1 score) = 67.1, FPS = 45
SAM 2: J&F (Jaccard-F1 score) = 77.0, FPS = 61.5
Segmentation Quality
SAM 1: mIoU (mean Intersection over Union) = 63.7
SAM 2: mIoU (mean Intersection over Union) = 70.8
User Interaction Efficiency
SAM 1: More user interactions required
SAM 2: Fewer user interactions required
Conclusion
SAM 2 marks a significant advancement in the field of visual segmentation, building on the foundation laid by SAM 1 and extending its capabilities to dynamic video environments. Its innovative architecture, enhanced efficiency, and reduced user interactions make it a powerful tool for a wide range of applications. With SAM 2, Meta's FAIR team has set a new benchmark for promptable visual segmentation, paving the way for future developments in this exciting field.
For more details, check out the SAM 2 demo and explore the Research paper, Github.
So guys, I hope you're enjoying my product management newsletter on Substack! I value your opinion. Please like, share, and comment to support me. Like the articles you find helpful, share my newsletter with colleagues and friends, and leave comments to spark discussion. I'd love to hear your thoughts, questions, and suggestions to shape future content. Your engagement is crucial in making this newsletter a valuable resource. Thank you for your support and for helping me improve
Loved your quick and thorough analysis.